1.1 目前已有的单目SLAM研究成果 Related Work
基于特征点提取法 (Feature-Based Methods)
The fundamental idea behind feature-based approaches (both filtering-based [15, 19] and keyframe-based [15]) is to split the overall problem – estimating geometric information from images – into two sequential steps:
图像特征点提取法的基本思想(可以是基于滤波方式[15,19]和基于关键帧方式[15])就是要解决从图像(帧)上估计空间的几何信息——这整一个问题,可以拆分成两个步骤:
图像特征点(基于滤波[15,19]和关键帧[15])方法的基本思路是把从图像(帧)估计几何信息的这个大问题,拆分成两步:
改动_Labby:基于特征的SLAM方法(包括滤波SLAM[15,19]和关键帧SLAM[15])的基本思想是将整个问题——从图像序列中估计几何信息——拆分成两步:
First, a set of feature observations is extracted from the image.
首先,从图像中提取一组特征观测量(feature observations)。
Second, the camera position and scene geometry is computed as a function of these feature observations only.
其次,相机位置和场景几何信息,仅通过上述特征观测量计算获得。
改动_Labby:然后以这些特征变量建立位姿估计函数,计算摄像头的位置信息和构建场景地图。
While this decoupling simplifies the overall problem, it comes with an important limitation:
虽然这种解耦(decoupling)方法简化了(估计空间几何信息的)整个问题,但是这种方法存在一个比较大的局限性:
Only information that conforms to the feature type can be used.
即:仅仅(提取)使用了图像上符合特征类型的信息,(而图像的其他数据信息将被丢弃掉,不被使用,译者额外添加备注)
In particular, when using keypoints, information contained in straight or curved edges– which especially in man-made environments make up a large part of the image – is discarded.
尤其是在使用关键特征点(keypoints)时,(其他)那些包含直边或曲边的图像信息——特别是构成绝大部分人造环境的,这样的图像信息,——被弃置。(翻译比较啰嗦)
改动_Labby:尤其是当使用特征点进行构图与定位时,图像中所包含的直线或曲线边缘信息——大量存在于当前的人工建筑环境中——则不会被考虑。
尤其是在使用关键特征点(keypoints)时,在很多人造环境中包含的直边和曲边都被弃置。(谢谢蔡育展老师指点)
Several approaches have been made in the past to remedy this by including edge-based [16, 6] or even region-based [5] features.
之前,已经有不少文章,提出了获取更多图像信息的方法,包括基于图像边缘特征提取(edge-based) [16, 6],甚至是基于图像区域特征提取(region-based) [5]。
Yet, since the estimation of the high-dimensional feature space is tedious, they are rarely used in practice.
然而,高维度空间的特征计算代价比较大,所以这些方法很少在实际中使用。
To obtain dense reconstructions, the estimated camera poses can be used to subsequently reconstruct dense maps, using multiview stereo [2].
如果要进行稠密式环境重构(dense reconstruction), 可以通过多视立体(multiview stereo)的方法,使用连续的相机估计姿态,来重构稠密地图[2]。
改动_Labby:为了重构稠密的环境地图,可以通过多视角立体几何理论,利用已经估计得到摄像头姿态来重构后续的稠密地图[2]。
图像直接法 Direct Methods.
Direct visual odometry (VO) methods circumvent this limitation by optimizing the geometry directly on the image intensities, which enables using all information in the image.
使用直接法的视觉里程计(VO,视觉里程计的英文简称)规避了特征点提取法的局限性,其方式就是通过直接对图像强度(即:图像像素灰度,译者额外添加备注)来优化空间几何信息,从而达到使用图像上所有信息的目的。
改动_Labby:直接法视觉里程计(VO)是直接利用图像像素点的灰度信息来构图与定位,克服了特征点提取方法的局限性,可以使用图像上的所有信息。
In addition to higher accuracy and robustness in particular in environments with little keypoints, this provides substantially more information about the geometry of the environment, which can be very valuable for robotics or augmented reality applications.
除了(直接法)具有较高的精度和算法鲁棒(的特点)外,特别是在那些特征点稀少的场景中,(相比特征点提取法,译者额外添加备注),实质上,直接法会获取更多的环境空间几何信息,这一点对机器人和增强现实的应用,是非常具有价值的。
改动_Labby:该方法在特征点稀少的环境下仍能达到很高的定位精度与鲁棒性,而且提供了更多的环境几何信息,这在机器人和增强现实额应用中都是非常有意义的。
While direct image alignment is well-established for RGB-D or stereo sensors [14, 4], only recently monocular direct VO algorithms have been proposed:
直接(配准)法(direct image alignment)(理论和应用)早已经在RGB-D或双目视觉传感器上建立(和应用)[14, 4],但是,基于单目相机,使用直接法,来计算视觉里程计的算法,是近些年才被提出来的:
In [24, 20, 21], accurate and fully dense depth maps are computed using a variational formulation, which however is computationally demanding and requires a state-of-the-art GPU to run in real-time.
在[24, 20, 21]中的论文中,提出使用泛函变分公式(variational formulation)来计算高精度,完全式稠密型深度地图(full dense depth maps),但是(这些方法的)计算量比较大并且需要实时运行在(高性能)GPU上并且实时运算时需要(高性能)GPU(硬件加速,译者额外添加备注)。
In [9], a semi-dense depth filtering formulation was proposed which significantly reduces computational complexity, allowing real-time operation on a CPU and even on a modern smartphone [22].
在[9]论文中,提出了一种半稠密型深度滤波器(semi-dense depth filtering)公式,它能够大大降低计算复杂度(计算量),并且可以实时运行在单个CPU上,(这个算法)甚至还可以跑在智能手机上[22]。
By combining direct tracking with keypoints, [10] achieves high frame-rates even on embedded platforms.
论文[10]提出直接跟踪法融合特征值提取法(的思想),该算法可以维持很高的图像帧率,甚至可以跑在嵌入式系统(,也可以保持较高的图像帧率。)(而不会因为图像算法处理量大,硬件资源有限等原因,产生图像掉帧的现象等等,译者额外添备注)
All these approaches however are pure visual odometries, they only locally track the motion of the camera and do not build a consistent, global map of the environment including loop-closures.
所有这些方法(的不足,缺点,译者额外添加备注),实质上是计算视觉里程计,它们仅仅只是在局部本地,范围内跟踪相机运动(和轨迹),并没有考虑创建一个全局,高度一致性的(比如说:漂移会产生“不良匹配”,导致地图重构不精准等,这样的问题,可以理解为环境重构的inconsistency,译者额外添加备注),场景地图,包括对闭环的处理等。
位姿图优化 Pose Graph Optimization
This is a well-known SLAM technique to build a consistent, global map:
图优化方式是SLAM解决全局地图一致性的一个重要手段:
The world is represented as a number of keyframes connected by pose-pose constraints, which can be optimized using a generic graph optimization framework like g2o [18].
世界(或者叫全局地图)由一连串(相机帧间运动经过的)相机关键帧组成,这些相机关键帧组成了(姿态图的)节点,并且由帧间的位姿关系作为约束条件相连接,这样一个(非线性)图状结构,可以通过像g2o [18] 那样的通用图优化框架(generic graph optimization framework)来优化求解(关键帧的相机姿态,译者额外添加备注)。
In [14], a pose graph based RGB-D SLAM method is proposed, which also incorporates geometric error to allow tracking through scenes with little texture.
在文献[14]中,提出了一种基于姿态图的RGB-D SLAM方法,该方法(不仅仅使用光度测量误差项,photometric error,译者额外补充说明备注)也用到(3D点云的)几何误差项,可以在环境纹理(特征点)稀少的场景中进行图像跟踪。
To account for scale-drift arising in monocular SLAM, [23] proposed a keypoint based monocular SLAM system which represents camera poses as 3D similarity transforms instead of rigid body movements.
为了处理单目SLAM引起的尺度漂移这个问题,论文[23]提出了基于关键帧的单目SLAM系统,(其主要思想就是)把相机位姿表示为3D相似变换(similarity transform)而不是用刚体运动(rigid body movements)来计算。
 image copy right belongs to engel14eccv paper, 图像摘录自 engel14eccv论文
image copy right belongs to engel14eccv paper, 图像摘录自 engel14eccv论文
图片说明文字
Fig. 1: Large-Scale Direct Monocular SLAM: LSD-SLAM generates a consistent global map, using direct image alignment and probabilistic, semi-dense depth maps instead of keypoints.
Fig. 1: 具备大尺度,基于直接法的单目SLAM系统: LSD-SLAM (英文简称) 通过对图像(Intensity)直接配准和使用概率模型来表示半稠密深度图,生成具有全局一致性的地图(这是不同于以往,使用特征点提取法的地图构建)。
改动_Labby: Large-Scale Direct Monocular SLAM 建议翻译为: 大尺度单目直接SLAM方法
Top: Accumulated pointclouds of all keyframes of a medium-sized trajectory (from a hand-held monocular camera), generated in real-time.
顶部示图:(使用手提持式单目相机,) 实时叠加,户外中长等距离相机轨迹上,所有关键帧(keyframe)对应的点云地图效果。
改动_Labby: (手持式单目相机)运动中等距离的过程中实时生成的轨迹图及所有关键帧对应的点云地图。
Bottom: A selection of keyframes with color-coded semi-dense inverse depth map. See also the supplementary video.
底部示图:(LSD-SLAM运行过程中,)相机轨迹中,部分关键帧图像以及对应的着色半稠密逆深度图(semi-dense inverse depth map)示意,详见补充视频内容。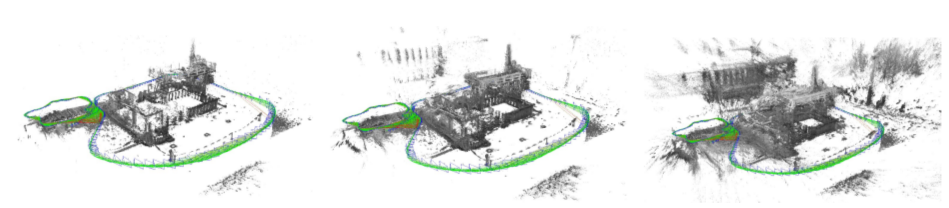 image copy right belongs to engel14eccv paper, 图像摘录自 engel14eccv论文
image copy right belongs to engel14eccv paper, 图像摘录自 engel14eccv论文
Fig. 2: In addition to accurate, semi-dense 3D reconstructions, LSD-SLAM also estimates the associated uncertainty.
Fig.2:LSD-SLAM 除了能够重构精准的半稠密三维空间地图(即,能够计算出深度,译者额外添加备注),它也能够估计相应深度值的不确定性(uncertainty)。
From left to right: Accumulated pointcloud thesholded with different maximum variance.
示图从左到右的顺序:(由于深度值的不确定性,我们使深度服从高斯分布模型,译者额外添加备注)选用不同的深度极大方差, 会呈现出不同效果的点云地图,(点云地图由稀疏到稠密,译者额外添加备注)。
Note how the reconstruction becomes significantly more dense, but at the same time includes more noise.
注意到,(即使是相同环境,译者额外添加),越显稠密的点云地图,往往夹杂着更多的(深度不确定性的,未能收敛的)噪点(,因为LSD-SLAM在计算深度的同时,也在估计深度值的不确定性,点云数量增加,自然而然深度未能收敛的点云数量也随之增加,译者额外添加备注)。